第一次实验内容
实验概述
使用R软件,运用NPV和IRR判定法则,完成对一项车位投资决策的方案的选择。通过实验,加深学生对于金融现金流、货币时间价值、投资决策判定法则的理解。
实验内容
- 了解R语言中变量、数值型变量、逻辑型变量、字符型变量的界定与运算。
- 了解R语言中列表、数据框及数据框切片与子集选择等概念界定与实际操作。
- 重点了解tidyverse系列包在数据处理中的运用。
- 运用所学知识解决实际投资决策问题
实验工具R(tidyverse,jrvFinance)
实验过程
- 结合老师给出的脚本,对基本数据操作进行了解,同时完成相关问题
- 综合运用数据分析工具和投资决策原则,对不同车位购买方案进行计算,并给出相关结论。
R语言包的运用
R语言的强大之处,在于它可以“即插即用”课中安装包,目前CRAN平台收录了近14000个包。
包的安装使用 install.packages(“包的名字”)这样的方法进行
如安装tidyverse包,可以使用install.packages(‘tidyverse’)这样的命令进行安装
数据类型
1. 数值型
数值型非常简单,就是我们日常说的数字,如12345,我们可以利用typeof()函数对数值型变量进行审视
a <- 1234
typeof(a)## [1] "double"2.逻辑型
逻辑型数据只有两种类型,真(TRUE)和假(FALSE),这两个字符是R语言的保留字符,同时可以简写为T和F
b <- F
typeof(b)## [1] "logical"3.字符型
字符型数据也就是字符串,文本格式的数据都是这类型的数据,如“四川农业大学”
text <- "四川农业大学经济学院"
typeof(text)## [1] "character"4.因子型
因子数据是R语言的特殊数据类型,它代表字符串和数字的的映射关系。
sex <- c("男","女")
sex_f <- as.factor(sex)
sex_f## [1] 男 女
## Levels: 男 女is.factor(sex_f)## [1] TRUE数据结构
数组
数组是有序的原始序列,可以存储多个同类型的数据。下面是一维数组的例子:
vec1 <- c(1,2,3)
vec1## [1] 1 2 3class(vec1)## [1] "numeric"cha_vec <- c("a","b","c")
cha_vec## [1] "a" "b" "c"class(cha_vec)## [1] "character"矩阵被称为二阶数组,包含了行和列两部分,不过矩阵内所有的元素都一种类型。在R中可以很方便的使用matrix()函数创建矩阵
m1 <- matrix(c(1,2,3,4,5,6),nrow=2)
m1## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6m2 <- matrix(c(1,2,3,4,5,6),nrow=2,byrow = T)
m2## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6args(matrix)## function (data = NA, nrow = 1, ncol = 1, byrow = FALSE, dimnames = NULL)
## NULL三阶或以上的数组,可以简单的理解为n维数组,很难在平面上展示n维数据。在R中需要使用array()定义高纬数,可以用?array查看帮助
array3 <- array(1:27,dim=c(3,3,3))
array3## , , 1
##
## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9
##
## , , 2
##
## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
##
## , , 3
##
## [,1] [,2] [,3]
## [1,] 19 22 25
## [2,] 20 23 26
## [3,] 21 24 27class(array3)## [1] "array"列表
列表是一个非常有特色的的数据类型,它有一点类似向量,但是R语言中允许列表存在不同的数据类型,甚至允许放入不同的数据结构,比如我们可以在一个列表中放入一个向量和一个矩阵。在R中可以使用list函数来定义一个列表。
一个形象的比喻列表就像一列火车,里面什么都可以装,什么时候用,什么时候拿出来非常灵活。
mix_list <- list(m1,cha_vec,array3)
mix_list## [[1]]
## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6
##
## [[2]]
## [1] "a" "b" "c"
##
## [[3]]
## , , 1
##
## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9
##
## , , 2
##
## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
##
## , , 3
##
## [,1] [,2] [,3]
## [1,] 19 22 25
## [2,] 20 23 26
## [3,] 21 24 27数据框
数据框是R中最重要的数据类型,也是我们接触到的最多的数据类型,大多数时候我们研究的数据都是以数据框的形式出现的。数据框也是由行和列组成,看起来和矩阵比较类似。
但是数据框的每一列都是一个数组,可以将其看成是由不同的素组组合而成;它的每一行可以看做一个列表,存放这不同的类型。列是数组,行是列表。看一个例子
head(iris)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa我们可以使用str()函数参考数据框结构
str(iris)## 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...我们可以看到,最后一列Species是因子型的数据,其他列都是数值型的数据。需要注意的是数据框一般都包含表头,它提供了关于该数据框的信息,如最后一列的名称为Species,可以知道这一列是关于物种类型的数据。
第一个小练习
1.创建一个字符变量,存储你的姓名。
2. 创建一个数值变量,存储你的身高(cm),同时创建一个数值变量存储体重(kg)
3. 创建一个一维数组(向量)存储你和你最好朋友的身高。
4. 随意创建一个4*4的矩阵
5. 尝试创建一个5维数组,使用array函数
6. 尝试创建一个列表,第一个元素存储之前创建的你和你最好朋友的身高数组。第二个列表元素,存储你和她(他)的名字的数组。
7. 观察一下R自带的airquality,和mtcars数据框,回答mtcars数据有多少列,多少行,其中是否存在因子类型的列
R中的程序控制
分支结构
所谓分支结构,就是在运行之前,需要对条件是否满足进行判断,如果符合条件,那么继续运行,否则就跳过。分支结构可以用if语句进行控制,举一个最简单的例子。
x <- 0
y <- 2
if(x>1) {
y <- 2.5
print(x)
} else {
y <- -y
}请大家思考一下,这样的表述后y是多少?
x <- c(0.05, 0.6, 0.3, 0.9)
for(i in seq(along=x)){
if(x[i] <= 0.2){
cat("Small\n")
} else if(x[i] <= 0.8){
cat("Medium\n")
} else {
cat("Large\n")
}
}## Small
## Medium
## Medium
## Largeifelse函数
函数ifelse()可以根据一个逻辑向量中的多个条件, 分别选择不同结果。如
x <- c(-2, 0, 1)
y <- ifelse(x >=0, 1, 0)
print(y)## [1] 0 1 1循环结构
循环结构就是要枚举所有可能的情况,并进行一次遍历,在R中使用循环的方法有两种,一种是使用for循环,从而遍历所有内容;另一种是用while循环,只要满足条件就一直执行,直到条件不满足
sum <- 0
for ( i in 1:5) {
sum = sum + i
print(i)
}## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5请大家思考如果我打印sum等于多少?
i <- 0
while (i<3) {
i = i + 1
print(i)
}## [1] 1
## [1] 2
## [1] 3# 牛顿法解x^3=100
x0 <- Inf
x1 <- 1 # 初始值
while (abs(x1-x0)>0.00001){
x0 = x1
y = x0^3
dy = 3*x0^2
x1 = x0 + (100 - y)/dy #向答案收敛
print(x1)
}## [1] 34
## [1] 22.6955
## [1] 15.19505
## [1] 10.2744
## [1] 7.165367
## [1] 5.426146
## [1] 4.749559
## [1] 4.644025
## [1] 4.64159
## [1] 4.641589函数式编程
函数就是一个封装好的程序,通过定义和运用,反复实现同一功能。R非常强调函数式编程。很多时候我们对一些内部函数的细节不需要进行细致的把握,只需要知道它是用来完成上面功能就可以了,我们可以不断地使用别人的包,调用别人写好的函数,实现自己需要的功能。在R中使用function定义一个函数,我们之前在债券课程中已经给大家展示了如何写函数。
函数名 <- function(形式参数表) 函数体
函数体是一个表达式或复合表达式(复合语句), 以复合表达式中最后一个表达式为返回值, 也可以用return(x)返回x的值。 如果函数需要返回多个结果, 可以打包在一个列表(list)中返回。 形式参数表相当于函数自变量,可以是空的, 形式参数可以有缺省值, R的函数在调用时都可以用“形式参数名=实际参数”的格式输入自变量值。
sq_sum <- function(x,y){
x^2 + y^2
}
sq_sum(5,3)## [1] 34稍微复杂一点的例子
f <- function() {
x <- seq(0, 2*pi, length=50)
y1 <- sin(x)
y2 <- cos(x)
plot(x, y1, type="l", lwd=2, col="red",
xlab="x", ylab="")
lines(x, y2, lwd=2, col="blue")
abline(h=0, col="gray")
}
f()
第二个小练习
写一个分支结构命令,进行如下判断:对之前自己建立的体重变量进行判断,当体重大于80kg,打印”注意控制体重“;当体重低于40kg,返回“你的体重偏轻”,当体重在40-80kg之间,打印”继续保持“
用for循环,计算100!(100的阶乘)
向量索引
R最基本的列向量索引是从1开始的.
a <- c(seq(2,6))
a## [1] 2 3 4 5 6a[1]## [1] 2a[2:4]## [1] 3 4 5a[-1]## [1] 3 4 5 6a[c(1,3,5)]## [1] 2 4 6同样我们之前介绍了逻辑变量,我们也可以使用逻辑判断来对向量中的元素进行索引
a[c(T,F,F,T,T)]## [1] 2 5 6# 我们也可以修改a向量中的某个位置的元素
a[2] <- 0
a## [1] 2 0 4 5 6a[2:4] <- c(0,0,1)
a## [1] 2 0 0 1 6#我也可以用逻辑判断批量修改a中的元素
a[a==0] <- 100大家可以思考一下,执行完上面最后一行,a变成什么样子了?
我们还可以做更为复杂的操作
v1 <- c(0.1,1,2,3,4)
v1[v1^2-v1>=0]## [1] 1 2 3 4数值向量的算术运算
数值向量的算术运算很简单,主要遵循两个原则:对相应位置的元素进行计算,并自动循环利用较短的向量(循环补齐功能)。
c(1,2,3,4)+1## [1] 2 3 4 5c(1,2,3,4) - c(2,3,4,1)## [1] -1 -1 -1 3c(1,2,3) *c(2,3,4)## [1] 2 6 12c(1,2,3)/c(2,3,4)## [1] 0.5000000 0.6666667 0.7500000c(1,2,3) ^2## [1] 1 4 9c(1,2,3)^ c(1,2,3)## [1] 1 4 27c(1,2,3,14) %% 2## [1] 1 0 1 0矩阵索引(矩阵子集)
矩阵进行索引时,第一个参数是行(row),第二个参数是列(column)
m1 <- matrix(1:9,nrow=3)
m1## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9# 选择第1列第2行的单个元素
m1[2,1]## [1] 2# 也可以选很多
m1[2:3,2:3]## [,1] [,2]
## [1,] 5 8
## [2,] 6 9m1[1,] #第一行## [1] 1 4 7m1[,2] #第二列## [1] 4 5 6m1[,1:2]## [,1] [,2]
## [1,] 1 4
## [2,] 2 5
## [3,] 3 6m1[,-3]## [,1] [,2]
## [1,] 1 4
## [2,] 2 5
## [3,] 3 6m1 > 3## [,1] [,2] [,3]
## [1,] FALSE TRUE TRUE
## [2,] FALSE TRUE TRUE
## [3,] FALSE TRUE TRUEm1[m1>3]## [1] 4 5 6 7 8 9class(m1[m1>3])## [1] "integer"矩阵运算
需要注意的是矩阵的乘法 %*%
m1 + m1## [,1] [,2] [,3]
## [1,] 2 8 14
## [2,] 4 10 16
## [3,] 6 12 18m1 - 2*m1## [,1] [,2] [,3]
## [1,] -1 -4 -7
## [2,] -2 -5 -8
## [3,] -3 -6 -9m1 *m1## [,1] [,2] [,3]
## [1,] 1 16 49
## [2,] 4 25 64
## [3,] 9 36 81m1 %*% m1## [,1] [,2] [,3]
## [1,] 30 66 102
## [2,] 36 81 126
## [3,] 42 96 150m1 ^2## [,1] [,2] [,3]
## [1,] 1 16 49
## [2,] 4 25 64
## [3,] 9 36 81m1/m1## [,1] [,2] [,3]
## [1,] 1 1 1
## [2,] 1 1 1
## [3,] 1 1 1#矩阵的转置我们可以使用t()函数进行
t(m1)## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 9数组和矩阵的合并
a <- c(1,2,3,4)
b <- c(5,6,7,8)
cbind(a,b) # 列合并## a b
## [1,] 1 5
## [2,] 2 6
## [3,] 3 7
## [4,] 4 8rbind(a,b) # 行合并## [,1] [,2] [,3] [,4]
## a 1 2 3 4
## b 5 6 7 8矩阵也可以进行行与列的合并
mm1 <- matrix(seq.int(2,24,2),nrow = 3)
cbind(mm1 ,m1)## [,1] [,2] [,3] [,4] [,5] [,6] [,7]
## [1,] 2 8 14 20 1 4 7
## [2,] 4 10 16 22 2 5 8
## [3,] 6 12 18 24 3 6 9第三个小练习
- 如何快速创建一个包含0,0.25,0.5,0.75,1,1.25,1.5,1.75,2的向量
- 了解diag函数的参数与作用,使用序列10到0到10(即10,9,…,0,1,2,…,10),创建一个21*21的矩阵
实验课最终两道题目
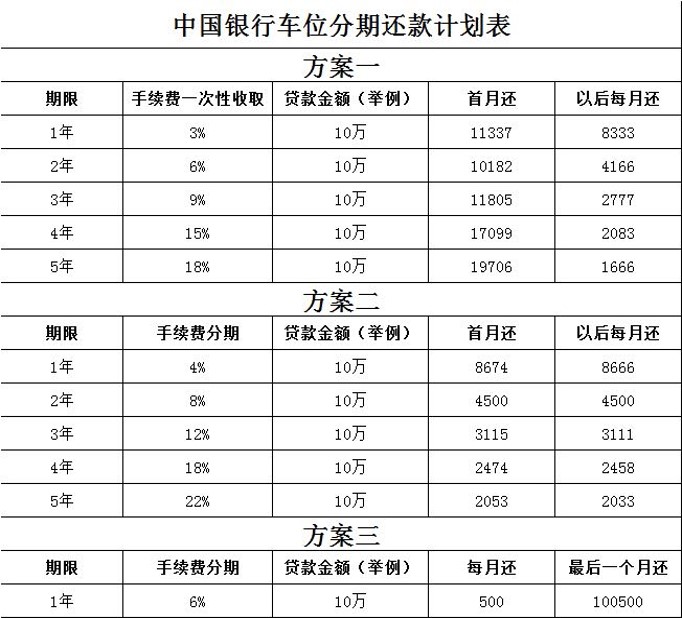
第一题,假设张老师要买车位,计算三种购车不同年限方案的融资成本(年化利率IRR),给出综合分析。